

多人数対話AI開発の課題を解決する「Qlean Dataset」の力
従来の音声データセットでは捉えきれなかった、3名の話者によるコメディ調の自然な掛け合いが、このデータセットの最大の魅力です。重なり発話や割り込み、テンポのある応答、話題転換といった、多人数会話特有の複雑な特性が多様に記録されています。これにより、以下のようなAI開発の課題解決に貢献します。
-
話者分離・話者追跡の精度向上: 誰が、いつ、何を話しているのかを正確に識別する技術は、会議議事録AIや音声エージェントにとって不可欠です。このデータセットは、実際の会話に近い環境で話者分離モデルの性能を検証し、汎化性能を高めるのに役立ちます。
-
自然対話理解・対話生成の高度化: コメディ調の会話は、感情の機微やユーモアの理解、即興的な発言、自然な間合いを含みます。これにより、AIがより人間らしく、共感性のある対話を生成できるようになるでしょう。
-
実利用環境に近いモデル検証: 自然な複数話者環境で収録されているため、開発中のAIモデルが実際の利用シーンでどれだけ機能するかを、より正確に評価できます。これにより、開発後の手戻りや調整コストを大幅に削減し、生産性向上に直結します。
データセットの魅力と詳細
このデータセットは、『Qlean Dataset』の機械学習用データセットラインナップ「AIデータレシピ」の一つとして提供されます。20代から50代の男女3名によるコメディ調の雑談やエピソードトークが、合計約100時間(1音声約20分〜30分)収録されています。データ形式はmp3/wav、音声レートは44.1kHzです。
具体的な話題例としては、恋愛相談、思い出話(初恋、笑える失敗談など)、マイブーム、趣味、流行、好きなお菓子についてなど、全約200話題が含まれており、多様な会話パターンを学習できます。

サンプル詳細はこちらで確認できます。
https://qleandataset.visual-bank.co.jp/lineup/pn-035
導入後の具体的な活用シーンとメリット
このデータセットは、研究用途から産業用途まで幅広いAI開発に活用できます。
-
研究用途での活用:
-
多人数会話における話者分離・話者推定研究: 3話者が同時に発話、割り込み、重なりを行う自然な音声データにより、多人数環境での話者識別や話者特徴抽出モデルの性能検証が可能です。
-
自然対話理解・会話行動分析研究: コメディ的なテンポ、即興性、話題転換を含むため、ターンテイキング、会話構造解析、話題遷移モデルの研究素材として活用できます。
-
自然言語処理×音声処理のマルチモーダル対話研究: 多人数トークの音声特徴を用い、対話生成モデルや発話予測モデル、応答最適化モデルの学習データとして使用できます。
-
-
産業用途での活用:
-
多人数会話対応の音声認識(ASR)エンジン開発: 重なり発話や割り込みを含む3話者データにより、会議AI、音声議事録生成AI、カスタマーセンター向け対話AIなど、実環境を想定したASR精度向上に活用できます。これにより、議事録作成の自動化による生産性向上や、カスタマーサポートの効率化によるコスト削減が見込めます。
-
対話型AI(音声エージェント・アシスタント)の自然対話生成: テンポのある掛け合いデータにより、対話生成モデルの自然さ、応答多様性、リアクション生成の精度改善に寄与します。顧客対応の質が向上し、競争力強化に繋がるでしょう。
-
マルチスピーカー音声処理技術の検証: 音声分離、話者追跡、音量・位置推定など、複数話者状況を前提とした音声処理アルゴリズムの開発に活用できます。
-
スタートアップがデータ調達で学ぶべきこと
AI開発において、質の高い学習データの確保は、スタートアップにとって特に大きな課題です。データ収集やアノテーションには多大な時間とコストがかかり、そのプロセスがボトルネックとなることも少なくありません。Qlean Datasetのような権利クリアで商用利用可能なデータソリューションを活用することは、この課題を効率的に解決する鍵となります。
-
コスト削減と時間短縮: 既存の権利処理済みデータセットを利用することで、ゼロからのデータ収集や法務チェックにかかる外注費や時間を大幅に削減できます。
-
開発サイクルの加速: 短期間で高品質なデータを手に入れることで、AIモデルの開発・検証サイクルを加速させ、市場投入までの時間を短縮できます。
-
法的リスクの軽減: 著作権や肖像権などの権利処理が済んでいるため、安心して商用利用でき、将来的な法的トラブルのリスクを軽減できます。
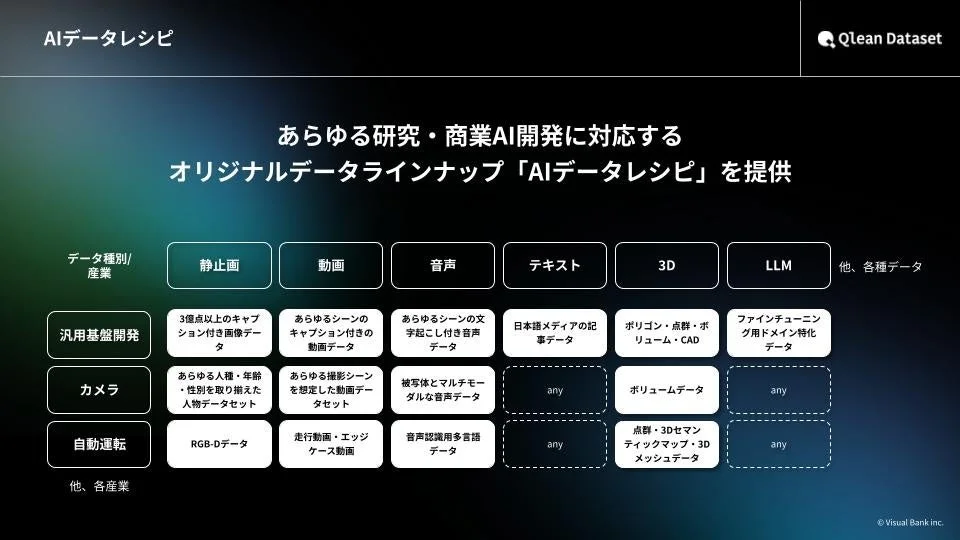
Qlean Datasetは、画像・動画・音声・3D・テキストなど多様な形式のデータに対応し、業界特化・最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しています。AI開発現場におけるデータ収集・整備の負荷を軽減し、法的リスクのないAI開発環境の構築を支援する、まさにスタートアップの心強い味方と言えるでしょう。


Qlean Datasetサイト:
https://qleandataset.visual-bank.co.jp/
AIデータレシピ:
https://qleandataset.visual-bank.co.jp/lineup
まとめ:AI開発の未来を拓くデータソリューション
Qlean Datasetの「日本語・3話者・コメディテーマトーク音声コーパスデータセット」は、多人数対話AIの精度向上を目指す開発者にとって、まさに待望のソリューションです。自然でリアルな会話データを活用することで、AIはより人間らしく、そして実用的な対話能力を身につけることができるでしょう。
このデータセットを導入することで、AI開発の生産性向上、コスト削減、そして市場における競争力強化という大きなメリットが期待できます。AI開発の新たな一歩を踏み出すために、ぜひQlean Datasetの活用を検討してみてはいかがでしょうか。